redis-py源码分析
本文会简述该库的代码组织架构,会着重介绍它实现的连接池ConnectPool以及如何实现的线程、进程安全。
文件结构
1 | . |
实现逻辑
1 | import redis |
看架构图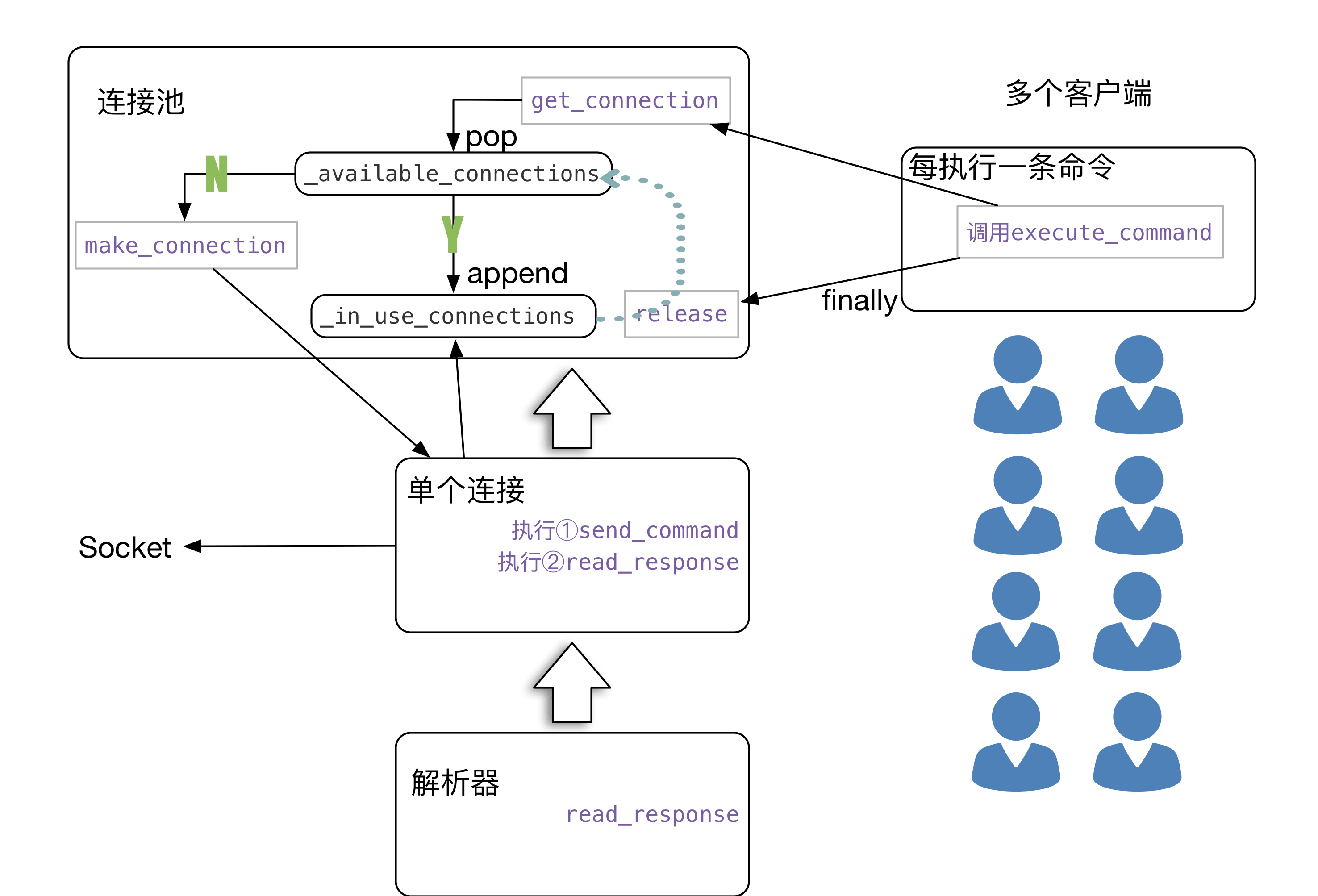
看调用图(以下为5年前的2.4版本)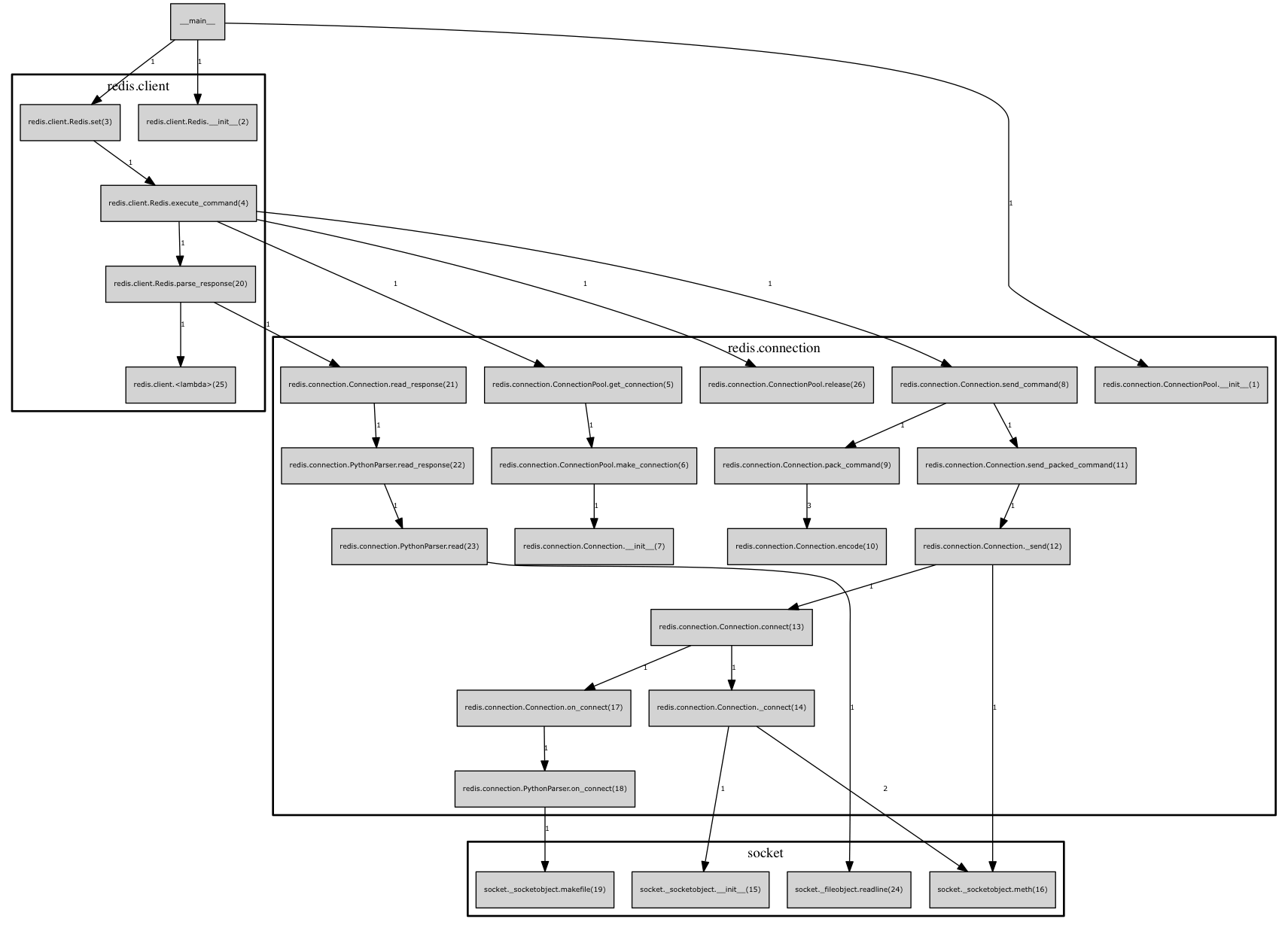
第一步执行r=redis.Redis()没进行什么操作,同时隐式的初始化了ConnectionPool。
等到执行set操作的时候。就是执行了execute_command,此时分为了几个步骤。看第5个函数调用,从连接池里面get_connection。如果没有可用的,那么则新建(redis.connection.Connection.init),此时并没有创建socket连接。第8个函数调用send_command,命令打包然后创建连接发送。该版本使用connection._sock.makefile(‘r’)便于读取。
再到了第21个函数调用Connection.read_response.使用解析器从socket读取数据并转换成便于python使用的数据结构
最后finally将该连接释放到线程池
现在可以看到有这样一条关系,每一个redis.Redis()实例都有一个ConnectionPool对象,一个连接池至少含有一条连接。所以绝大多数情况没有必要写出连接池
1 | pool = redis.ConnectionPool() |
多线程
如果你的程序是单线程的。那么没什么好说的,一个Redis实例,一个连接池,一个socket连接。
多线程那我们主要考虑的是线程安全问题。对于redis客户端就是socket连接绝对要线程间隔离,否则一个线程解析了另外一个socket的返回内容,那么多线程也就没意义了。测试一下
1 | import time |
可以看到结果并没有错误,而且创建的连接数和创建的线程数并不是一致的
试想一下,每次执行一次类似set的指令。都会从连接池(List结构)取出(pop)一个连接。而list.pop是线程安全的。执行完毕命令后又会使用append加入到连接池,list.append也是线程安全的。所以针对socket的操作是线程隔离的。这一切好像和_in_use_connections并没有什么关系。对于一个简单的连接池。从连接池取出,用完加入到连接池。而_in_use_connections记录的是使用中的线程。啥子用呢。它用于一个接口(关闭连接池中的所有连接)。注意关闭连接并不会将_available_connections和_in_use_connections清空。它只会将connection对象中的_sock设置为None,而每次执行命令的时候connection都是会检查_sock是否为空,如果为空则会重新建立连接,如下示例
1 | import redis |
因为它关闭连接的时候并没有将对应的connection对象从连接池中删除。那么会造成一个问题。如果你创建过100个连接,那么连接池将会一直复用这些对象。如果你高峰期创建过多的连接,而后又只需要几个连接就够了(虽然这样的问题估计极少会遇到)。你可以显式的pop出_available_connections并关闭。
其实有一个地方是非线程安全的。在创建连接的时候有self._created_connections += 1,如果你访问这个值得到创建的连接数是不可靠的。不过这都无关紧要,因为你不可能在极短的时间内创建许多连接。即使这里不准。统计误差也不会有2个。
为了避免无端创建出N多连接。该客户端后期加入了BlockingConnectionPool类。使用LifoQueue创建出连接队列,如果该队列被使用完,那么后续请求将会阻塞一段时间,过长则引发异常。
多进程安全
redis-py在2.4.12加入了多线程安全见issues。
可以看到实现原理也是很简单的。fork进程的时候socket一样使用的。为了分开,使用了os.getpid()区分。如果进程号变了,则关闭所有的连接,重新连接后自然就分开了。同时为了防止一个进程有多个线程这种情况。一个线程关闭后,另外一个线程也可能执行关闭操作。所以此处使用了锁
1 | def _checkpid(self): |
插播一下当前2.10.5版本的调用图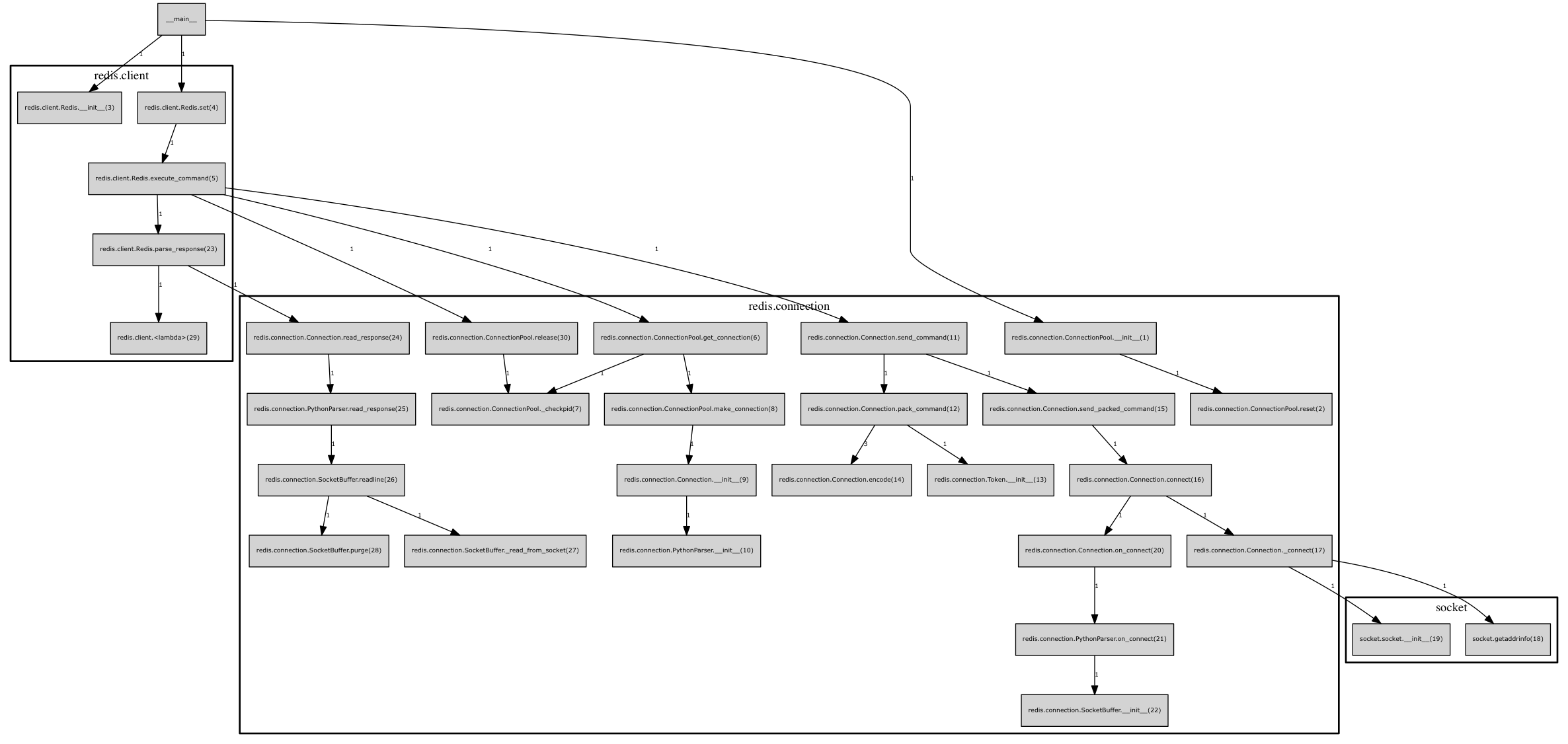
可以看到和最上面的调用图出入很小,仅仅加入了进程安全,将socket.makefile变成了SocketBuffer.
分布式锁
线程锁就是多线程间有线程间共享变量。进程锁就是多进程间有进程间共享变量。此处的共享变量就是将变量存储到redis数据库。实现也比较简单。截取一段acquire看看
1 | def do_acquire(self, token): |
另外它实现的只是最简单的锁。比如可重入锁啥的都是没有实现的。如果你想配合sentinel进行高可用。往下看…..
Sentinel
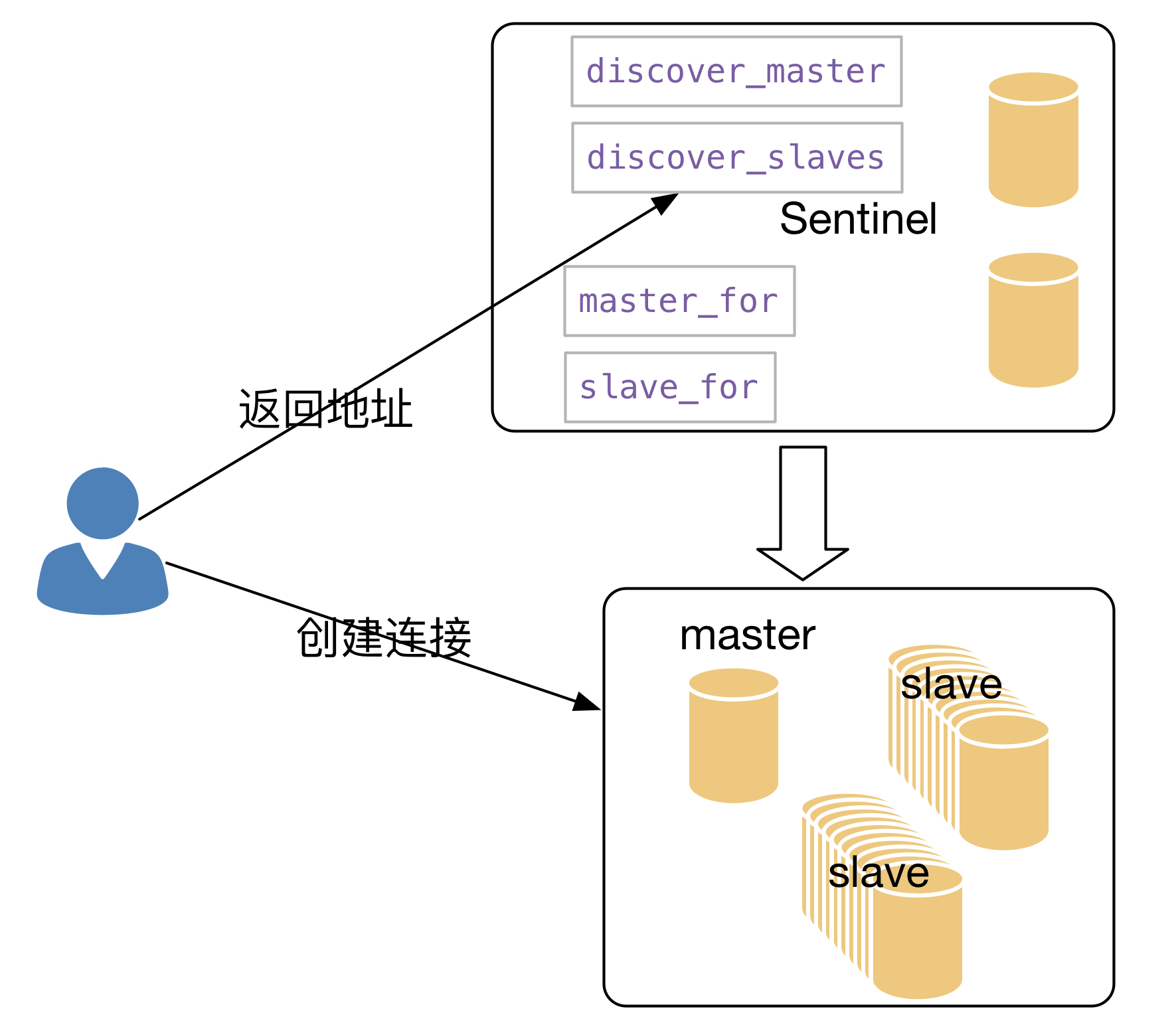
得益于redis-py的松耦合,连接池、连接、解析器基本都很独立。
客户端和监视器组创建一个上面说的Redis正常连接。它主要提供接口返回master的地址和返回salve的地址。
然后我们使用master_for返回的也是一个Redis连接
1 | return redis_class(connection_pool=connection_pool_class( |
不过它进行对连接池和连接对象都进行了一些修改。可以看到它将self传递给了底层连接池。而连接池也使用self.connection_kwargs['connection_pool'] = weakref.proxy(self)将自己传递给了底层Connection,就这样它实现了高可用客户端,在底层连接的时候使用高层提供的函数提供正确的地址~~

 官方网站:
官方网站: