ocr.ficapy.com 后台实现
因为个人需求,写了一个很小众的作品,https://ocr.ficapy.com,我给它起的项目名是pdfaddtext,用途是给扫描版本的PDF文件加上搜索功能。使用场景是我有几本扫描版本的PDF书籍(网上有特别多的扫描版书籍),有时候想搜索书中有没有提到某个知识点,纯图片是无法搜索的,你只能凭记忆去找。本项目作用就是将PDF的文本内容识别出来,然后写入一层隐藏的文字层,这样PDF阅读器就能够搜索这些文字了,同时尽量保证将识别出来的文字写到原图片对应的位置,类似的工具有OCRmyPDF,它的缺点很明显,使用Tesseract OCR引擎,对比识别效果,简直被商用OCR吊打。
最开始有了这个想法,我大概花费了一个下午的时间用python写出了基本的demo。将每一页PDF转换成图片,然后用免费的OCR服务去识别,得到结果,最后合并出一个新的pdf出来。过程算是比较顺利。本着独乐乐不如众乐乐的心态。我计划将它转变成一项web服务,于是挖坑之旅就此开始了
TLDR
开始的构思是这个样子的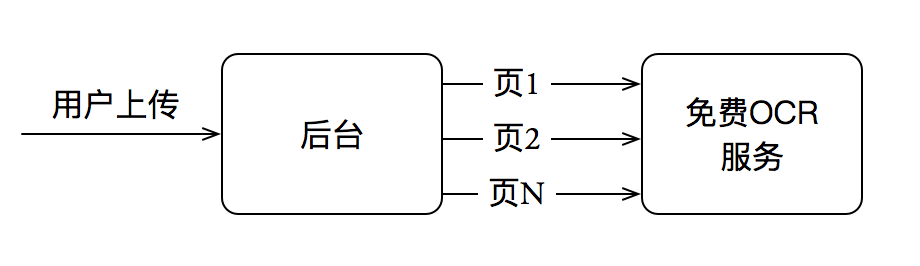
后台接收到文件进行拆分,依次获取结果最后服务端生成文件返回给客户端。流程完成,是不是特简单😕
问题一: pdf转换生成jpg效率过低
python的生态无需质疑,各种包齐全到你怀疑人生。pdf转换成jpg也都是有的,比如pdf2image。它有一个无法忽视的缺点,效率太低。个人处理少量问题可以,但是如果用于web服务。每生成一张照片卡两秒,肯定无法忍受,后来对比imagemagick和ghostscript,ghostscript的效率比imagemagick高一些,当然比python不知道高到哪里去了。注: imagemagick的pdf转图片底层使用的是ghostscript,最后选择了subprocess调用ghostscript
问题二: OCR效率过低
目前没有能力搭建一个识别准确度比较高的文字识别引擎,于是使用了免费的OCR。在网上腾讯的免费OCR口碑是很不错的,超高的识别准确率,而且看文档发现不限制识别次数,只是不保证并发(是不是感觉超级良心!)。醒醒了少年,哪里有这么好的事情!!!
我刚开始用的时候大概四五秒返回结果。识别准确率网上没有瞎吹,对中文的准确率还是很不错的,后来可能该服务用的人太多,效率大幅度降低。降低到10到20秒才会返回结果。而且经常性返回系统繁忙的错误。这也可能和我的需求有关,因为我上传的识别素材都是1000像素以上的图片。里面的文字众多,所以识别效率比较低。但是腾讯提供的免费OCR服务有劣化服务质量的嫌疑,毕竟如果免费的服务提供的过于的好,用户付费的热情肯定大幅度降低。很明显的是你上传一张图片得到结果,之后再次上传依旧是等待十几秒才得到结果,稍微正常的开发肯定都知道将结果缓存一下,再次相同的图片请求直接返回结果。鉴于腾讯OCR的低效,我不得不找其他的OCR服务同时使用,保证系统的可靠性,最终同时使用了以下服务
开发过程中的个人感觉,识别准确率依次是百度>腾讯>搜狗>微软>faceplusplus
1 | 分别是百度 腾讯 搜狗 微软 face++ 对同一张简单图片的识别结果 |
基本上国内能免费使用的OCR服务我都给想办法整合了,它们的输出都差不多,提供文字在图片中的定位功能,除了腾讯返回很慢,其他服务基本都在四秒左右返回。搜狗的OCR服务很低调,好像知道的人都不多,而且是这些服务里面文档最奇葩的,文档几乎没有,就提供了一个PHP调用服务的demo。
即便同时使用了五个免费服务,依旧不够用,而且几乎除了腾讯是不限制每日调用次数,其他的服务都会限制每天最多调用多少次。最后预估每天可供识别的图片数量最多不超过3000页。底层OCR服务的限制直接导致了设计复杂度的成倍上升,如果本地能在500毫秒内识别得到一个结果,也就没那么多事儿了。
问题三:更快的响应
如果是单人使用,那么一个任务进行完毕之后再进行下一个任务。不存在并发调度的问题。但是它作为一项web服务,势必会存在并发问题,当某个用户正在执行转换操作,此时另外一个用户又提交了一个任务请求。是选择继续将前面的任务执行完毕再执行后续的(先到先服务),还是采取一定的策略进行乱序执行。本程序选择了短任务优先策略,以pdf中的单页作为最小任务单元,使用优先级队列对任务进行排序。将每一个任务未完成的页数作为比较元素。每次选择任务的时候总是从优先级中选择未完成页数最少的任务优先执行。同时为了避免饥饿,假设存在几百页的大文件,每隔一分钟,按照任务的创建时间来调整任务优先级
最开始的最简架构几乎是认为不存在并发的。但是不并发是不可能的,所以流程改成了这样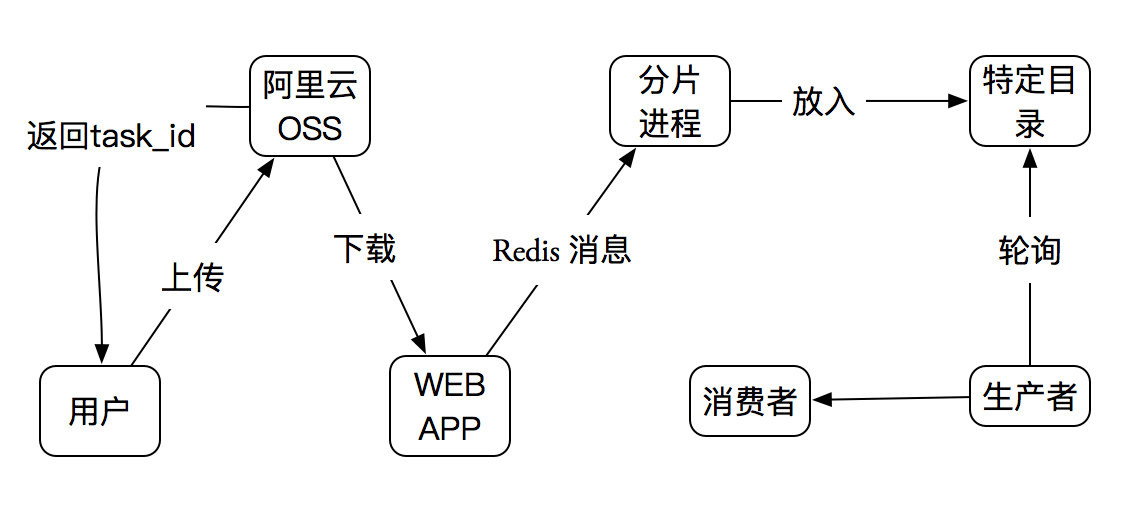
- 用户将图片上传到阿里云OSS, 后台接收到回调后下载文件。返回给客户端任务id。
- 客户端根据此ID创建websocket连接。后台下载文件完毕后发送redis队列消息。
- 开启一个独立的PDF分片进程。接收到消息后进程获取文件地址,然后将PDF文件的每一页转换成图片(放到特定的目录)。
- 生产者负责轮询目录发现新生成的图片。然后每一张图片被封装成一个Task任务对象,被加入到全局队列,全局队列的基本格式是一个字典{file_md5:Queue},每一个文件都拥有一个队列。
- 消费者负责从队列中获取一个任务。获取的规则是从优先级队列中找到第一个文件md5。然后在全局队列中对应文件md5队列中取出一个任务,执行任务,更新优先级队列,如果该文件被全部执行完成则返回结果
这里涉及到了三个很重要的地方、Task任务、全局队列、优先级队列。其中第五步是整个过程中最容易出现错误的地方。
后台整个是使用Tornado实现的,最开始我考虑的是将PDF分片使用multiprocess进程来实现就好了。后来考虑它要是挂了怎么办。如果它挂了整个流程就无法进行。如果一定要将它使用multiprocess,那么将不得不监控它是不是挂掉了对它进行重启。最后还是将它独立出来用supervisord处理了
问题四: 锁&死锁
上图中的消费者和生产者并不是简单的共享同一个任务队列。消费者取出任务的流程是先读取优先级队列得到文件md5,再从全局队列字典中获得相应队列获得任务。设想程序最开始从优先级队列里面取得的是空值。再用空值去查找全局队列无疑会被报错。要么你就在获取任务的时候使用while语句不断的判断当前优先级任务队列是否有元素。然而在Tornado里面死循环这种方式是不允许的,会直接造成其他部分无法执行,无法响应用户请求。因此需要使用Tornado提供的tornado.lock.Event。在读取优先级队列之前先判断该事件锁是否被锁。如果被锁那么coroutine就被阻塞。这样只需要在优先级队列添加和删除元素的地方统一处理。添加元素的时候取消锁。取消元素的时候判断优先级队列是否为空。为空则设置锁
为了不浪费系统资源。如果一个用户的任务正在被执行,而此时用户退出了。毫无疑问,这种情况下本着快速响应的原则,我们会直接删掉该文件的所有任务。再删掉任务之前,该文件在优先级队列中排列在最前面,因此,就有可能有的消费者获取了该文件的队列锁。然而{file_md5: Queue}任务队列被删除,意味着获取到锁的消费者永远无法被执行,造成死锁,该消费者再也无法消费任务。亦或者一个文件任务在未完成之前所有的消费者都会去读取这个队列,当任务被完成的时候(该队列会被删除)总有消费者还在持有该锁。避免方法是获取锁设置超时时间(比如五秒),如果没有获取到任务直接报告异常,捕获异常,返回一个空任务,消费者对空任务忽略处理,等待再次去全局队列获取任务,此时刚才的文件队列应该已经删除了。
注: 系统重启的时候清空redis优先级队列(后来想了一下优先级队列不必要放在redis当中,直接python实现也是可以的,它并没有持久化的需求)
问题五: 何时触发redis消息,何时将任务加入到优先级队列
这好像不是一个问题。最开始的时候我选择在文件下载完成后发送redis消息并加入到优先级队列。
先想这样一个问题,当用户断开后为了节省资源势必会选择立刻删掉优先级队列(同时删掉全局队列的相关项TODO:我好像没有考虑两个用户正在处理同一个PDF一个用户断线的情况)。假设用户是非正常断开(它过几秒后会再次连接,我是不是闲的蛋疼。考虑这种情况😕)。为了更好的体验会选择前端重连机制。我们希望重连后任务能恢复并继续。如果在下载完成后发送redis消息。那么websocket重连就不会发消息了。此时这个任务就没办法继续了
你会想,前端重连我也可以采用模拟重新上传文件的步骤啊~~~,too navie! 上传的时候添加了google验证码这一步。重新模拟上传自动化是做不到的。所以发送redis这一步再建立websocket连接后发比较合适
问题又来了。建立websocket后文件还没有下载完毕,此时发送redis消息到分片进程,分片进程无疑会出错。解决方法就和上面那个锁一样。添加Event事件锁,下载的时候执行set
1 | download_event = {} |
优先级队列可供选择的地方就更多了
- 文件下载完成后
- websocket建立连接后
- 生产者添加任务后
这里最重要的是不要在多个地方插入同一个事件,出了问题不好debug。下载完成前标志着第一次建立连接,websocket有可能标志着断线重连。它们最终都会走向生产者这个地方,所以我选择在生产者这里添加。先检测该file_md5是否存在对应的websocket连接,如果存在则加入全局队列,同时加入优先级队列
优化一:重复文件直接得到结果
如果文件在后台数据库存在记录,如果该文件全部结果都正确存在则直接返回结果。如果正在被执行或者有部分内容没有被OCR。则后台新建任务,总而言之,避免用户再次上传文件到阿里云OSS
优化二:减少OCR次数
OCR的机会很宝贵,所以应该尽量减少OCR的次数,首先想到的是同一个文件如果得到了结果就不需要再次去调用OCR接口,再其次,一个PDF文件由N张图片组成。对每一张图片进行相似度判断,如果足够相似就认为它是同一张图片避免再次执行识别操作。图片相似度算法前面有博文提到,使用的是imagehash。对每张图片生成64bit的标识。比对的时候使用汉明距离检查是否相似。数据库优化汉明距离的方法前面博文也有提到
优化三: 使用浏览器客户端进行PDF合并
如果用户上传的文件为100M,在后台生成文件并提供给用户下载,OSS外网下载的价格大概是1G五毛。嗯。上传几个大文件,来几次恶意下载,等着天价账单吧😀。因此这种应用采取客户端渲染是很有必要的,我先找了一下js的库。号称”任何能够用JavaScript实现的应用系统,最终都必将用JavaScript实现”~~,然并卵,我并没有找到允许修改PDF文件的开源js库,关于PDF的要么是渲染用,要么就是从0生成一个新的PDF文件。后来我找到了商业的js库pspdfkit(也有一些其他的,当然它们价格都不菲),它让我知道了有webassembly这个东东的存在,它允许c/c++/rust代码再浏览器端执行。虽然c/c++/rust我一个都不会, 但是我还是找到了一个c++的库PDF-Writer,看到了希望的曙光内心是激动的。然后我去刷C的教程,再刷了一遍C++的教程,知道了Hello World怎么写。参照了几个webassembly的项目(大多数都是用C写的)。重点参照了这个wasm-image-compressor。最终还真给折腾出来了(前端耗费的时间占据了整个开发的一大半)。结果是编译后大小为1.5M,实现了两个功能。验证PDF文件是否有效(可以正常解析,页数是否符合要求,每页大小是否符合要求),传入PDF文件和json结果,生成一个新的文件。
别说效率还真不错,生成文件过程比python快很多
该项目提供了两种生成PDF的方式,浏览器端 和python脚本,这两种方式生成的PDF文件方式是不一样的。python的方式是合并两个图层,新的canvas图层透明度为完全透明.c++的方式是采取追加的方式,设置每个元素的可见性为不可见
其次是字体的问题,写入文字的时候都需要指明字体。然而附带一个完整的字体会浪费巨大的空间。我找了一个比较小一点的中文字体,大小是1.5M。感觉这些文字不需要真正的显示出来,所以自己制作一个最小的字体带她这个中文字体是有可能的,但是我失败了。制作出来后电脑能够正常识别,C++库结果无法正常打开该字体
优化四: 采用msgpack进行传输
直接对结果进行json编码传输还是很不划算的,因此本项目数据存储以及前后端传输采用msgpack进行压缩后传输。需要注意的是websocket对二进制流需要特殊指定
1 | const socket = new WebSocket(url); |
改进方向
- 目前20页的限制让网页端几乎没有作用,提供一个稍有质量的本地OCR,对于数百页的PDF选择在本地识别
- 解决中文字体过大的问题,同时优化前端大小,尽量让压缩后的页面加载大小到1M以内
- 后台对PDF进行预处理,如果发现可直接读取文字表示该页不需要被OCR
- 改进前端发布逻辑,每次变动文件名让CDN缓存很尴尬
参考
Faster conversions from PDF to PNG/JPEG, imagemagick vs ghostscript

 官方网站:
官方网站: